Cloudflare desmente ataque cibernético ou sequestro de BGP em queda do 1.1.1.1
- Cyber Security Brazil
- 18 de jul. de 2025
- 3 min de leitura


A Cloudflare, gigante da infraestrutura de internet, veio a público para esclarecer a recente interrupção em seu serviço de resolução de DNS 1.1.1.1, que ocorreu em 14 de julho. Contrariando especulações disseminadas nas redes sociais sobre um possível ataque cibernético ou sequestro de BGP (Border Gateway Protocol), a empresa afirmou categoricamente em um relatório pós-mortem que a causa raiz do incidente foi, na verdade, uma configuração interna incorreta.
A interrupção impactou a maioria dos usuários do serviço em todo o mundo, tornando serviços de internet inacessíveis em diversos casos. "A causa raiz foi um erro de configuração interna e não o resultado de um ataque ou de um sequestro de BGP", declarou a Cloudflare, buscando dissipar rumores que ganharam força online.
A Cloudflare explicou que a origem da queda remonta a uma mudança de configuração realizada em 6 de junho, destinada a um futuro serviço do Data Localization Suite (DLS). Por um erro, essa alteração vinculou incorretamente os prefixos IP do Resolver 1.1.1.1 a um serviço DLS que não estava em produção.

O momento crítico ocorreu em 14 de julho, às 21:48 UTC (18:48, horário de Brasília). Uma nova atualização adicionou um local de teste ao serviço DLS inativo, o que, por sua vez, atualizou a configuração da rede globalmente e aplicou a configuração incorreta.
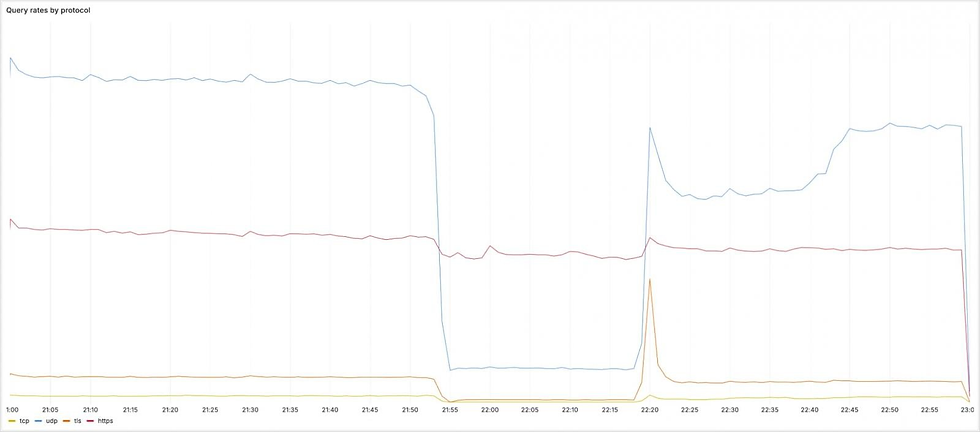
Este erro fez com que os prefixos do Resolver 1.1.1.1 fossem retirados dos data centers de produção da Cloudflare e, inadvertidamente, roteados para um único local offline. O resultado foi a inacessibilidade global do serviço.
Em menos de quatro minutos após a ativação da configuração errônea, o tráfego DNS para o Resolver 1.1.1.1 começou a cair drasticamente. Às 22:01 UTC (19:01, horário de Brasília), a Cloudflare detectou o incidente e rapidamente o divulgou ao público, demonstrando agilidade na comunicação. A reversão da configuração incorreta foi iniciada às 22:20 UTC (19:20, horário de Brasília), com a Cloudflare começando a reanunciar os prefixos BGP que haviam sido retirados. A restauração completa do serviço em todas as localidades foi alcançada às 22:54 UTC (19:54, horário de Brasília).
O incidente afetou múltiplas faixas de IP, incluindo o 1.1.1.1 (resolver DNS público principal), 1.0.0.1 (resolver DNS público secundário), 2606:4700:4700::1111 e 2606:4700:4700::1001 (resolvers DNS IPv6 principal e secundário), além de diversas outras faixas IP que suportam o roteamento dentro da infraestrutura da Cloudflare.
Em relação aos protocolos, as consultas UDP, TCP e DNS-over-TLS (DoT) para os endereços mencionados sofreram uma queda significativa no volume. No entanto, o tráfego DNS-over-HTTPS (DoH) foi amplamente afetado de forma diferente, uma vez que segue um roteamento distinto via cloudflare-dns.com.
A Cloudflare admitiu que a configuração incorreta poderia ter sido evitada caso a empresa utilizasse um sistema que realizasse uma implementação progressiva, atribuindo a falha ao uso de sistemas legados. Por essa razão, a empresa planeja desativar esses sistemas mais antigos e acelerar a migração para novos sistemas de configuração.
Esses novos sistemas utilizarão topologias de serviço abstratas, em vez de vinculações estáticas de IP, permitindo uma implantação gradual, monitoramento de saúde em cada etapa e reversões rápidas caso surjam problemas.
A empresa também ressaltou que, apesar de a configuração incorreta ter passado por uma revisão por pares, ela não foi detectada devido à documentação interna insuficiente das topologias de serviço e do comportamento de roteamento. Essa é uma área que a Cloudflare também se comprometeu a aprimorar, visando prevenir futuras ocorrências de incidentes similares.
Via - BC


